고정 헤더 영역
상세 컨텐츠
본문
2.4 명령어 세트(instruction set)
○ 어떤 CPU를 위하여 정의되어 있는 명령어들의 집합
명령어 세트 설계를 위해 결정되어야 할 사항들
1. 연산 종류 (Operation repertoire) : CPU가 수행할 연산들의 수와 종류 및 복잡도
2. 데이터 유형 (data type) : 연산을 수행할 데이터들의 형태, 데이터의 길이(비트 수), 수의 표현 방식 등
3. 명령어 형식 (instruction format) : 명령어의 길이, 오퍼랜드 필드의 수와 길이 등
4. 주소지정 방식 (addressing mode) : 오퍼랜드의 주소를 지정하는 방식
2.4.1 연산의 종류
CPU가 수행할 수 있는 연산들의 종류는 컴퓨터에 따라 매우 다양하다.
기본적인 연산들의 종류
1. 데이터 전송 : 레지스터와 레지스터 간, 레지스터와 기억장치 간, 기억장치와 기억장치 간에 데이터를 이동하는 동작
2. 산술 연산 : 덧셈, 뺄셈, 곱셈, 및 나눗셈과 같은 기본적인 산술 연산들
3. 논리 연산 : 데이터의 각 비트들 간에 대한 AND, OR , NOT, XOR 연산
4. 입출력(I/O) : CPU와 외부 장치들 간의 데이터 이동을 위한 동작들
5. 프로그램 제어 : 명령어 실행 순서를 변경하는 연산들 [ 분기(branch), 서브루틴 호출(Subroutine call) ]
서브루틴 호출을 위한 명령어들
CALL 명령어 : 현재의 PC내용을 스택에 저장하고 서브루틴의 시작 주소로 분기하는 명령어
RET 명령어 : CPU가 원래 실행하던 프로그램으로 복귀(return)시키는 명령어
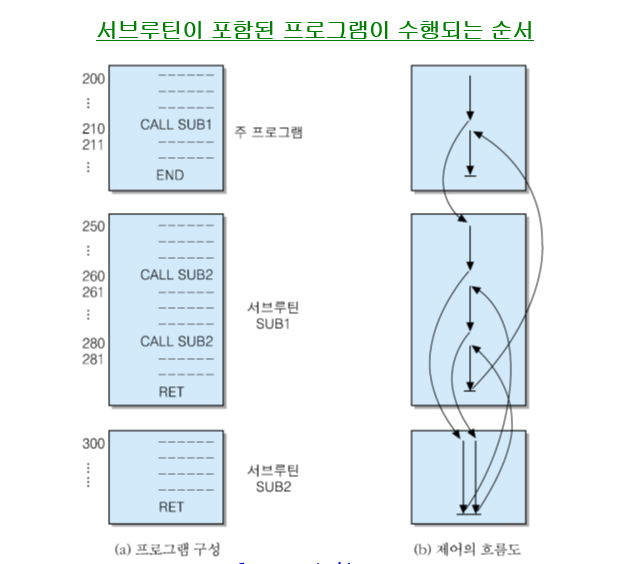
CALL/RET 명령어의 마이크로 연산
1. CALL X :

○ 현재의 PC 내용(서브루틴 수행 완료 후에 복귀할 주소)을 SP가 지정하는 스택의 최상위(top of stack : TOS)에 저장
○ 만약 주소지정 단위가 바이트이고 저장될 주소는 16비트라면, SP = SP -2 로 변경
2. RET :

○ SP에 저장된 내용을 다시 PC로 복귀
그림 1 수행 과정에서 스택의 변화
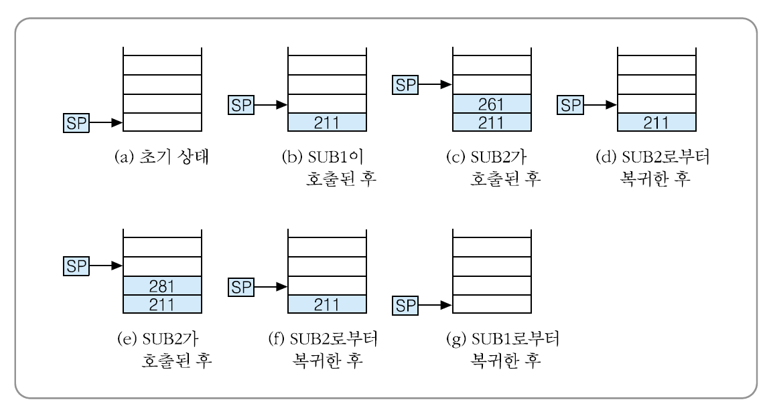
2.4.2 명령어 형식
명령어의 구성요소들
1. 연산코드 (Operation Code) :
○ 수행될 연산을 지정 (EX : LOAD, ADD )
2. 오퍼랜드 (Operand) :
○ 연산을 수행하는데 필요한 데이터 혹은 데이터의 주소
○ 각 연산은 한 개 혹은 두 개의 입력 오퍼랜드들과 한 개의 결과 오퍼랜드를 포함
○ 데이터는 CPU레지스터, 주기억장치, 혹은 I/O장치에 위치
3. 다음 명령어 주소 (Next Instruction Address) :
○ 현재의 명령어 실행이 완료된 후에 다음 명령어를 인출할 위치 지정
○ 분기 혹은 호출 명령어와 같이 실행 순서를 변경하는 경우에 필요
명령어 형식 (Instruction format) : 명령어 내 필드들의 수와 배치 방식 및 각 필드의 비트 수
필드 (Field) : 명령어의 각 구성 요소들에 소요되는 비트들의 그룹
명령어의 길이 = 단어(word) 길이 (한 번에 CPU가 처리할 수 있는 비트들의 그룹)
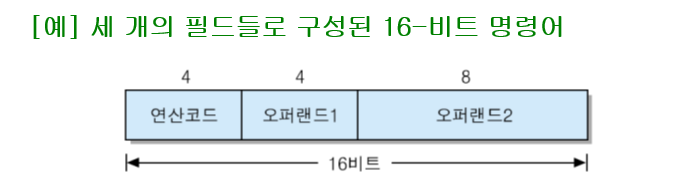
명령어 형식의 결정에서 고려할 사항들
1.연산 코드 필드 길이 : 연산의 개수를 결정
Ex) 4 bit -> 2^4 = 16 가지의 연산 정의 가능
※ 만약 연산 코드 필드가 5 bit로 늘어나면 2^5 = 32가지 연산들 정의 가능 -> 다른 필드의 길이가 감소
2. 오퍼랜드 필드의 길이 : 오퍼랜드의 범위 결정
오퍼랜드의 종류에 따라 범위가 달라짐
○ 데이터 : 표현 가능한 수의 범위 결정
○ 기억장치 주소 : CPU가 오퍼랜드 인출을 위하여 직접 주소를 지정할 수 있는 기억장치 용량 결정 (바이트)
○ 레지스터 번호 : 데이터 저장에 사용될 수 있는 레지스터의 개수 결정
EX) 오퍼랜드1은 레지스터 번호를 지정하고, 오퍼랜드2는 기억장치 주소를 지정하는 경우
오퍼랜드1 : 4bit -> 2^4 = 16 개의 레지스터 사용 가능
오퍼랜드2 : 8bit -> 2^8 = 256 -> 기억장치의 주소 범위 : 0 ~ 255번지
EX) 두 개의 오퍼랜드들을 하나로 통합하여 사용하는 경우
○ 오퍼랜드가 2의 보수로 표현되는 데이터라면, 표현 범위 : -2048 ~ +2047
○ 오퍼랜드가 기억장치 주소라면, 2^12 = 4096 개의 기억장치 주소들 지정 가능
오퍼랜드의 수에 따른 명령어 분류
1-주소 명령어 : 오퍼랜드를 한 개만 포함하는 명령어 (다른 한 오퍼랜드는 묵시적으로 AC가 됨)

2-주소 명령어 : 두 개의 오퍼랜드를 포함하는 명령어

3-주소 명령어 : 세 개의 오퍼랜드들을 포함하는 명령어

[EXAMPLE 1-주소 명령어]
길이가 16비트인 1-주소 명령어에서 연산 코드가 5비트인 경우의 명령어 형식을 정의하고, 주소지정 가능한 기억장치 용량을 결정하라
명령어 형식 :

주소지정 가능한 기억장치 용량 = 2^11 -> 2048
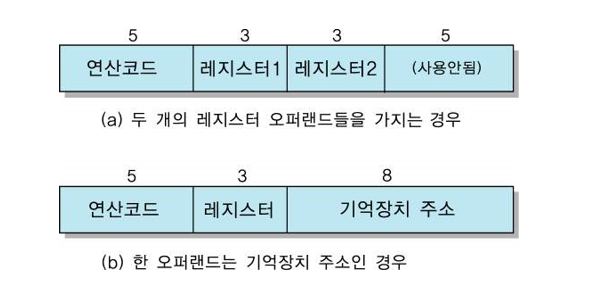
[EXAMPLE 2-주소 명령어]
16bit CPU에서 연산 코드가 5비트이고, 레지스터의 수는 8개이다. (a) 두 오퍼랜드들이 모두 레지스터 번호인 경우와, (b) 한 오퍼랜드는 기억장치 주소인 경우의 명령어 형식을 정의하라.
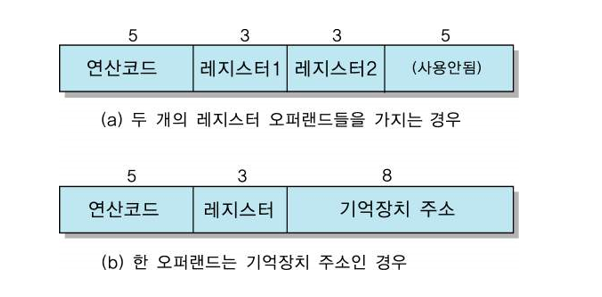
[EXAMPLE 3-주소 명령어]
명령어 형식이 프로그래밍에 미치는 영향
[EXAMPLE] X = (A+B) * (C-D)
1-주소 명령어를 사용한 프로그램 (프로그램 길이 : 7)

2-주소 명령어를 사용한 프로그램 (프로그램 길이 : 6)

3-주소 명령어를 사용한 프로그램 (프로그램 길이 : 3)
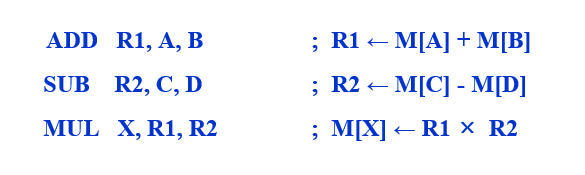
단점 : 명령어의 길이가 증가한다. 명령어 해독 과정이 복잡해지고, 실행시간이 길어진다.
2.4.3 주소지정 방식(addressing mode)
명령어 실행에 필요한 오퍼랜드의 주소를 결정하는 방식
다양한 주소지정 방식을 사용하는 이유 :
제한된 수의 명령어 비트들을 이용하여, 사용자(프로그래머)가 여러 가지 방법으로 오퍼랜드의 주소를 결정하도록 해주며, 더 큰 용량의 기억장치를 사용할 수 있도록 하기 위함
명령어 내 오퍼랜드 필드의 내용
○ 기억장치 주소 : 데이터가 저장된 기억장치의 위치를 지정
○ 레지스터 번호 : 데이터가 저장된 레지스터를 지정
○ 데이터 : 명령어의 오퍼랜드 필드에 데이터가 포함
EA : 유효 주소(Effective Address) 데이터가 저장된 기억장치의 실제 주소
A : 명령어 내의 주소 필드 내용 (오퍼랜드 필드의 내용이 기억장치 주소인 경우)
R : 명령어 내의 레지스터 번호 (오퍼랜드 필드의 내용이 레지스터 번호인 경우)
(A) : 기억장치 A번지의 내용
(R) : 레지스터 R의 내용
주소지정 방식의 종류
1. 직접 주소지정 방식 (direct addressing mode)
2. 간접 주소지정 방식 (indirect addressing mode)
3. 묵시적 주소지정 방식 (implied addressing mode)
4. 즉시 주소지정 방식 (immediate addressing mode)
5. 레지스터 주소지정 방식 (register addressing mode)
6. 레지스터 간접 주소지정 방식 (register-indirect addressing mode)
7. 변위 주소지정 방식 (displacement addressing mode)
> 상대 주소지정 방식 (relative addressing mode)
> 인덱스 주소지정 방식 (indexed addressing mode)
> 베이스-레지스터 주소지정 방식 (base-register addressing mode)
1. 직접 주소지정 방식 (direct addressing mode)
오퍼랜드 필드이 내용이 유효 주소(EA)가 되는 방식 [ EA = A ]
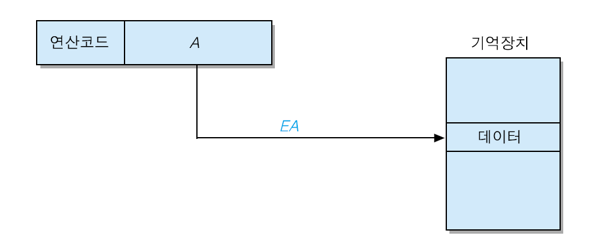
장점 : 데이터 인출을 위하여 한 번의 기억장치 엑세스만 필요
단점 : 연산 코드를 제외하고 남은 비트들만 주소 비트로 사용 가능 하기 때문에, 직접 저장할 수 있는 기억장소의 수가 제한
2. 간접 주소지정 방식 (indirect addressing mode)
오퍼랜드 필드에 기억장치 주소가 저장되어 있지만, 그 주소가 가리키는 기억 장소에 데이터의 유효 주소를 저장해두는 방식 [ EA = (A) ]
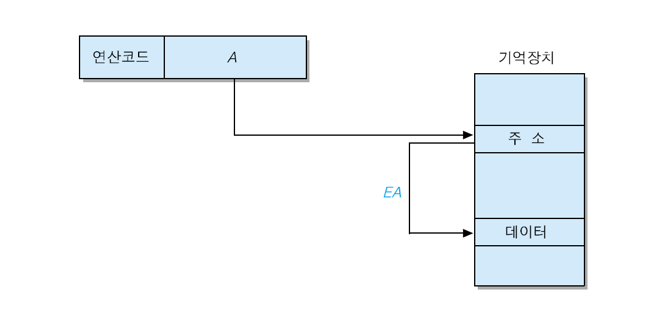
장점 : 최대 기억장치용량이 단어의 길이에 의하여 결정 -> 주소지정 가능한 기억장치 용량 확장
> 단어 길이가 n비트라면, 최대 2^n개의 기억 장소에 대한 주소 지정이 가능
단점 : 실행 사이클 동안에 두 번의 기억장치 엑세스가 필요
> 첫 번째 엑세스 : 주소 인출, 두 번째 엑세스 : 그 주소가 지정하는 기억 장소로부터 실제 데이터 인출
명령어 형식에 간접비트(I) 필요
○ 만약 I = 0 이면, 직접 주소지정 방식, I = 1 이면, 간접 주소지정 방식 -> 간접 사이클 실행

다단계(multi-level) 간접 주소 지정 방식 : EA = ((..(A)..))
3. 묵시적 주소지정 방식 (implied addressing mode)
명령어 실행에 필요한 데이터의 위치가 묵시적으로 지정되는 방식
Ex) SHL 명령어 : 누산기의 내용을 좌측으로 쉬프트, PUSH R1 명령어 : 레지스터 R1의 내용을 스택에 저장
장점 : 명령어 길이가 짧음
단점 : 종류가 제한됨
4. 즉시 주소지정 방식 (immediate addressing mode)
데이터가 명령어에 포함되어 있는 방식, 즉 오퍼랜드 필드의 내용이 연산에 사용할 실제 데이터

용도 : 프로그램에서 레지스터나 변수의 초기 값을 어떤 상수값으로 set하는 데 사용
장점 : 데이터를 인출하기 위하여 기억장치를 엑세스할 필요가 없음
단점 : 상수값의 크기가 오퍼랜드 필드의 비트 수 에 의해 제한됨
5. 레지스터 주소지정 방식 (register addressing mode)
연산에 사용될 데이터가 내부 레지스터에 저장되어 있는 경우로서, 명령어의 오퍼랜드가 해당 레지스터를 가리키는 방식 [ EA = R ]
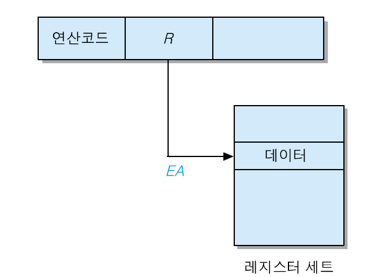
장점 : 오퍼랜드 필드의 비트 수가 적어도 됨. 데이터 인출을 위하여 기억장치 엑세스가 필요 없음
단점 : 데이터가 저장될 수 있는 공간이 CPU 내부 레지스터들로 제한
6. 레지스터 간접 주소지정 방식 (register-indirect addressing mode)
오퍼랜드 필드(레지스터 번호)가 가리키는 레지스터의 내용을 유효 주소로 사용하여 실제 데이터를 인출하는 방식 [ EA = (R) ]
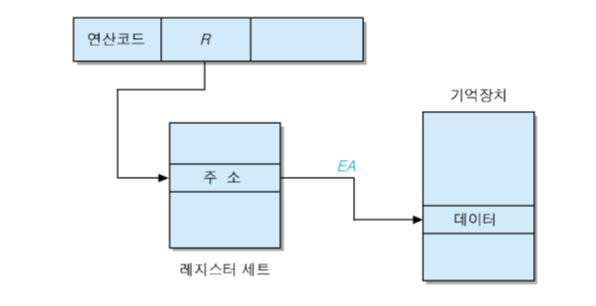
장점 : 주소지정 할 수 있는 기억장치 영역이 확장
> 레지스터의 길이 = 16bit라면, 주소지정 영역 : 2^16 = 64Kbyte
> 레지스터의 길이 = 32bit라면, 주소지정 영역 : 2^32 = 4Gbyte
7. 변위 주소지정 방식 (displacement addressing mode)
직접 주소지정과 레지스터 간접 주소지정 방식의 조합 [ EA = A + (R) ]
사용되는 레지스터에 따라 다양한 변위 주소지정 방식 가능
○ PC -> 상대 주소지정 방식 (relative addressing mode)
○ 인덱스 레지스터 -> 인덱스 주소지정 방식 (indexed addressing mode)
○ 베이스 레지스터 -> 베이스-레지스터 주소지정 방식 (base-register addressing mode)
상대 주소지정 방식(relative addressing mode)
프로그램 카운터(PC)를 레지스터로 사용하여 EA를 계산 EA = A + (PC) 단, A는 2의 보수
주로 분기 명령어에서 사용
A > 0 : 앞(forward)방향으로 분기
A < 0 : 뒷(backward)방향으로 분기
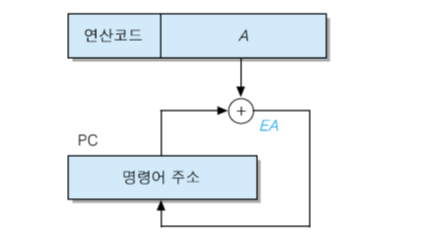
장점 : 전체 기억장치 주소가 명령어에 포함되어야 하는 일반적인 분기 명령어보다 적은 수의 비트만 필요
단점 : 분기 범위가 오퍼랜드 필드의 길이에 의해 제한 (오퍼랜드 비트들로 표현 가능한 2의 보수 범위)
인덱스 주소지정 방식(indexed addressing mode)
인덱스 레지스터의 내용과 변위 A를 더하여 유효 주소를 결정 EA = A + (IX)
IX : 인덱스 레지스터 : 인덱스 값을 저장하는 특수 목적 레지스터
주요 용도 : 배열 데이터 엑세스
EX) 데이터 배열이 기억장치의 500번지부터 저장되어 있고, 명령어의 주소 필드에 500이 포함되어 있을 때, 인덱스 레지스터의 내용 (IX) = 3 이라면 -> 데이터 배열의 네 번째 데이터 엑세스
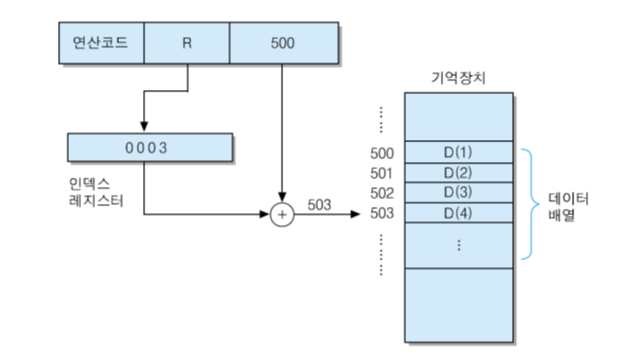
자동 인덱싱 (AUTO-INDEXING) : 명령어가 실행될 때마다 인덱스 레지스터의 내용이 자동적으로 증가 혹은 감소
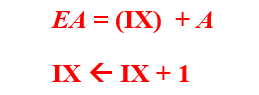
베이스-레지스터 주소지정 방식 (base-register addressing mode)
베이스 레지스터의 내용과 변위 A를 더하여 유효 주소를 결정 EA = A + (BR)
주요 용도 : 프로그램의 위치 지정(혹은 변경) 에 사용
Ex) 다중프로그래밍환경에서 프로그램 코드 및 데이터를 다른 위치로 이동시켜야 할 때, 분기 명령어나 데이터 엑세스 명령어들의 주소 필드 내용을 바꿀 필요 없이, BR 레지스터의 내용만 변경하면 된다.
----------------------------------------------------------------------------------------------------------------------------
기억장치에서 용량을 나타내는 단위는 바이트 와 단어
단어의 길이는 cpu가 실행할 명령어의 길이 혹은 내부 연산에서 한 번에 처리할 수 있는 데이터 비트 수와 같다.
주소지정 단위 :
각 바이트에 대해 별도 주소를 지정할 수 있고, 각 단어 별로 주소를 지정할 수 있다.
CPU가 발생하는 주소 비트의 수 A와 주소지정 될 수 있는 기억장소들의 수 N의 관계는 2^A = N이다.
여기서 바이트 단위로 지정한다면 기억장치의 용량은 N바이트.
단어의 길이가 32비트(4바이트)인 시스템에서 단어 단위로 지정한다면 용량은 N단어, 즉 4N바이트가 된다.
'Computer Science > Computer Architecture' 카테고리의 다른 글
| 03. 컴퓨터 산술과 논리 연산(2) [논리 연산, 시프트 연산] (0) | 2020.04.08 |
|---|---|
| 03. 컴퓨터 산술과 논리 연산 (1) [ALU의 구성 요소, 정수의 표현] (0) | 2020.04.08 |
| 02. CPU의 구조와 기능 (2) [명령어 파이프라이닝] (0) | 2020.04.03 |
| 02. CPU의 구조와 기능 (1) [CPU의 기본구조, 명령어 실행] (0) | 2020.04.03 |
| 01. 컴퓨터 시스템 개요 (0) | 2020.03.20 |





댓글 영역